The major new features are:
* Human readable contents behind the Arachne URIs (places, topographical units, objects)
* Improved matching labels using regular expressions
* Annotation of Arachne objects
1. Human readable content behind an URI
This means that the URIs in the annotations can now be used to check what lies behind them and deliver the results in a human friendly form. Normaly an URI is "just" an Identifier, but If you copy the URI of Arachne Dataset to your adressbar the Brower redirects you to the identified Arachne Entity in the Arachne Database. The URI can also be used as an URL.
Examples:
Object: http://arachne.uni-koeln.de/entity/1075708
Place: http://arachne.uni-koeln.de/entity/1206008
Topographical Unit: http://arachne.uni-koeln.de/entity/5152
2. The matching of the labels from Pleiades has been enhanced in the following way:
The old matching like described in step 2 has been enhanced by using regular expressions in the SQL-queries. Regular Expression are a standard, for the expression of text-search patters. These expressions .The Pleiades labels have been cleaned of any regular expression characters like . ? * [ ] and (), which would interfere with the matching process. In addition labels smaller than three characters are ignored because with the regular expressions they could create too many meaningless matches. The new matching, for example, handles that the labels of the Pleiades data set are correctly matched to fields that contain enumerations of Place names.
For Example a field with alternative Placenames contains "athen,atenes,athens" Then it wont match exactly to the string "athen" (the german Version). Its a substring of the String "athen,atehes,athens".
On the otherhand we don't want to match "athen" with "rathenow". Rathenow is not even near Athens. This Problem can only be solved with an Text search pattern like a Regular Expressions.
Also some bugs have been fixed that unintentionally lead to skipping some Pleiades labels in the matching process.
3. Annotations of Arachne Objects:
The data has also been extended, so now the annotations contain links to objects, which form the largest part of the Arachne Database. For every matched place in Arachne the objects that refer to these places are collected.
for example:
A Pleiades Places Links an Arachne Place which Links some Arachne Objects.
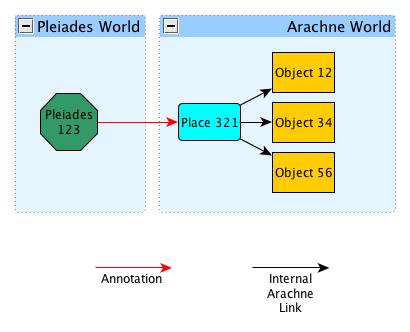 Now the script links the Arachne Objects directly to the Pleiades Place, skipping the Arachne Place.
Now the script links the Arachne Objects directly to the Pleiades Place, skipping the Arachne Place.

This is done in context of Step 4.
These changes sound quiet small but they have an imense impact. The bugfix and some other changes have been more than doubling the ammount of Arachne Place to Pleiades Place annotations. The Annotations of Objects nearly exploded. As seen in the Example pictures each Place Link creates several Annotations linking Arachne Objects to Pleiades Places.
Connections Links these tend to explode. If the average Arachne Place is connected to 5 Arachne Objects there are 5 Times more Pleiades Place to Arachne Objects Annotations than there are Pleiades Place to Arachne Place annotations!